梯度下降
xt+1:=xt−η∇f(xt)x^{t+1} := x^t - \eta \nabla f(x^t)
xt+1:=xt−η∇f(xt)
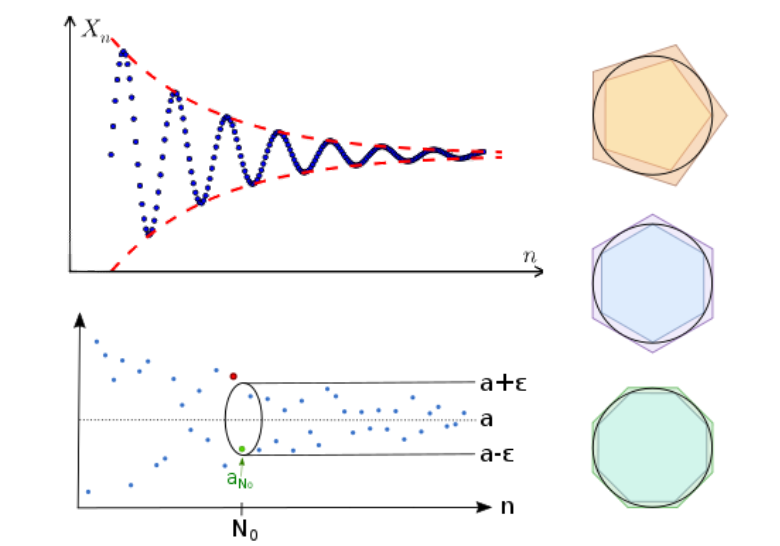
为了让 f(x)f(x)f(x) 的值越来越小,需要不断迭代优化 xxx 的值,xxx 优化是方向是 fff 的梯度的反方向,快慢受到学习率 η\etaη 的影响。
梯度下降的本质
梯度下降的本质是,将目标函数 f(x)f(x)f(x) 近似为其在某点 xtx_{t}xt 处的一阶泰勒展开,记为 fˉ(x;xt)\bar{f}(x;x_{t})fˉ(x;xt) :
f(x)≈fˉ(x;xt)=f(xt)+f′(xt)(x−xt)f(x) \approx \bar{f}(x;x_{t})=f(x_{t})+f^\prime(x^t)(x-x^t)
f(x)≈fˉ(x;xt)=f(xt)+f′(xt)(x−xt)
注意,只有在 xt→xx_{t}\to xxt→x 时误差 f(x)−fˉ(x;xt)f(x)-\bar{f}(x;x_{t})f(x)−fˉ(x;xt) 才趋近于 0,所以,我们要在 xtx_{t}xt 附近找一点 xt ...
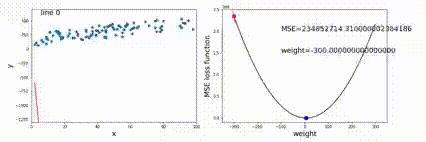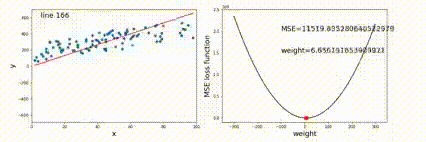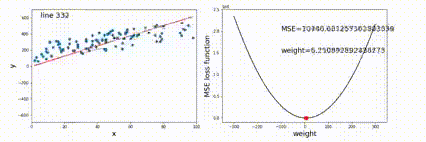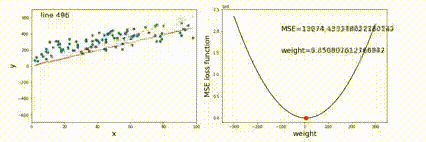
线性回归
普通线性回归 Linear Regression
一般形式
f(x)=w1x1+...+wkxk+bf(x)=w_1x_1+...+w_kx_k+b
f(x)=w1x1+...+wkxk+b
需要优化的参数为权重wnw_nwn与偏置bbb,通常使用最小二乘法估计模型参数。
一般写作向量形式:
f(x)=wx+bf(x)=wx+b
f(x)=wx+b
其中 w=(w1,...,wk)Tw=(w_1,...,w_k)^Tw=(w1,...,wk)T,x=(x1,...,xk)x=(x_1,...,x_k)x=(x1,...,xk)
优化(最小二乘法)Least Square Method
目标是求出一组参数w,bw,bw,b,使得对于所有输入的预测值与输出值的 MSE 最小。
定义MSE为:
E=∑in(f(xi)−yi)E = \sum_i^n(f(x_i)-y_i)
E=i∑n(f(xi)−yi)
优化目标是
w∗,b∗=arg minw,bEw^*,b^*=\argmin_{w,b} E
w∗,b∗=w,bargminE
一元线性回归的最小二乘法推导
E ...
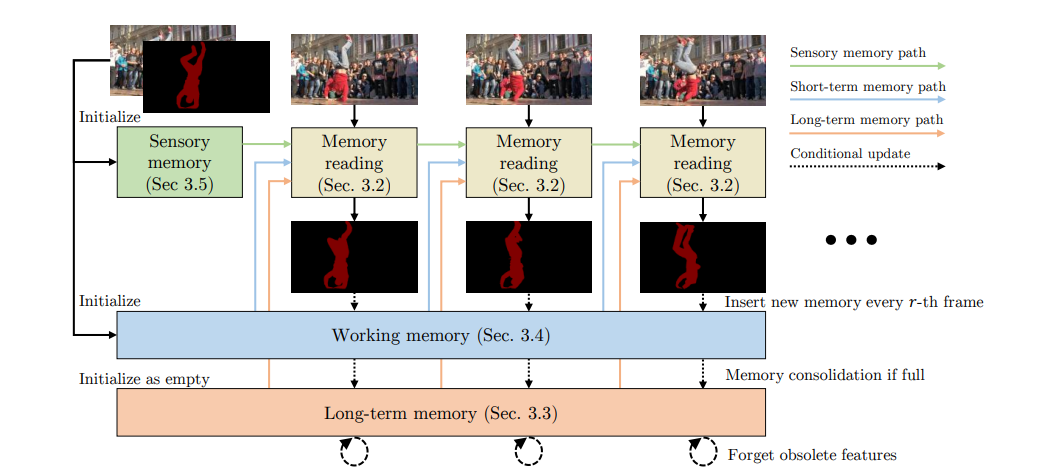
XMem
使用了三种类型的特征记忆(感官记忆,工作记忆,长期记忆)使得可以处理长视频而不会导致显存占用量过大,同时在短视频上也有良好的性能。为了定期将工作记忆中的重要特征整合到长期记忆,还开发了一个记忆增强算法。
三种记忆简介
感觉记忆:短期存储的低层次信息,如物体位置,是通过每帧将模型中Decoder中的多尺度特征,馈送至一个GRU传递、更新得到一个的隐藏表示。每隔 r 帧,会通过将模型掩码经过 Value Encoder的输出与感觉记忆经过另外一个 GRU 来深度更新(Deep Update)感官记忆。
工作记忆:可以在几秒钟的范围内实现准确的匹配,由一个键与一个与之对应的值组成,每隔 r 帧,将当前帧中 QueryEncoder输出的Query 作为工作记忆的键,输出的掩码经过一个值编码器的输出作为工作记忆的值。
长期记忆:存储一些紧凑而有代表性的特征,从而提高分割质量,当工作记忆达到一个上限时,就会通过一个内存整合过程,从工作记忆(working memory)中选择一些原型,并用一个内存增强算法整合到长期记忆。过于久远的记忆也会被丢弃。
利用记忆
感觉记忆与长期记忆
感觉记忆与长 ...

RepVGG
在VGG的基础上,结合了ResNet,在VGG的 Block 中加入了1×11 \times 11×1 卷积分支和残差分支。并在训练时,通过重参数融合了3×33 \times 33×3 卷积、1×11 \times 11×1 卷积与 残差连接到一个单独的 3×33 \times 33×3 卷积中,大大减少了模型宽度,以节约显存。
将 3 x 3卷积与BatchNorm结合为单个 3 x 3 卷积
卷积层,卷积参数为 WWW,卷积操作为 W(⋅)W(\cdot)W(⋅)
Conv(x)=W(x)+bConv(x) = W(x) + b
Conv(x)=W(x)+b
BatchNorm
BN(x)=γx−meanvar+βBN(x) = \gamma \frac{x-mean}{\sqrt{var}} + \beta
BN(x)=γvarx−mean+β
卷积+BatchNorm
BN(Conv(x))=γW(x)+b−meanvar+βBN(Conv(x)) = \gamma \frac{W(x) + b-mean}{\sqrt{var}} + \beta
BN(Conv(x))=γ ...
SwinTrack
概述
基于 Siamese 框架的简单而高效的全注意力跟踪模型。
提出了motion token,编码了目标的历史轨迹,通过提供时间上下文来改进跟踪性能,且轻量不影响速度。
SwainTrack 由三个部分组成:
用于特征提取的 Swin-Transformer主干网络。
用于视觉-运动特征融合的编码器-解码器网络。
用于分类与边界框回归的头部网络。
方法
Swin-Transformer
与 ResNet 相比,Swin-Transformer 能够提供更紧凑的特征表示和更丰富得到语义信息。
与 Siamese 网络一致,SwinTrack 需要Template与search两个输入,两个输入都如 Swin-Transformer 的处理方式一样,被分割为不重叠的 patch 送入网络,分别得到 φ(z)\varphi(z)φ(z) 与 φ(x)\varphi(x)φ(x)。
视觉-运动特征编码器-解码器
编码器
将template特征 φ(z)\varphi(z)φ(z) 与search特征 φ(x)\varphi(x)φ(x) 简单的拼接得到混合表示 fm1f^1_m ...
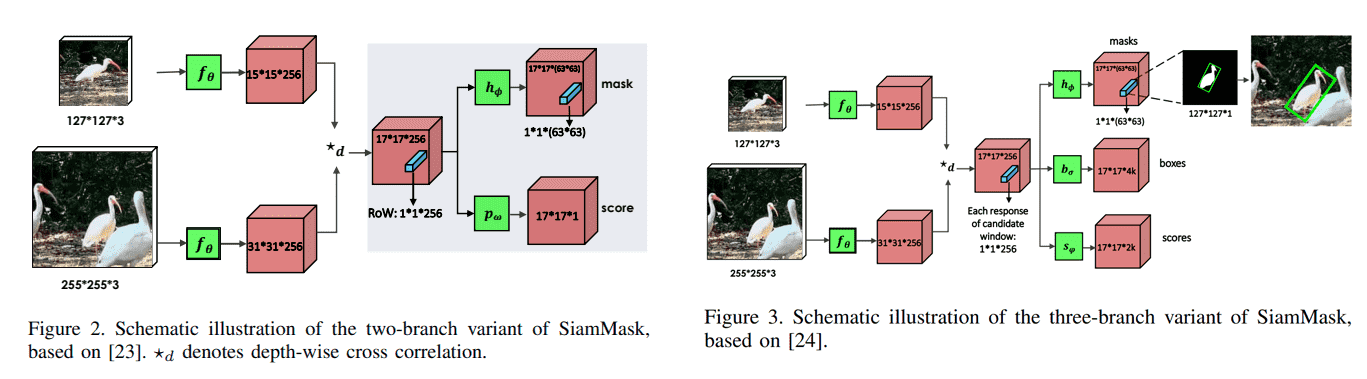
SiamMask
概述
兼顾视频对象分割与目标追踪。
由于是通过分割再根据掩码划出边缘框,拥有相当高的精度,但是也导致网络无法应对被遮挡的情况。
分为两个部分,其中第二个部分有两种结构:
Siamese网络:分别提取template与search输入图像的特征,进行通道互相关。
第二部分:
二分支结构:
Score 分支:目标是区分每个 row 是目标对象or背景。
Mask 分支:为每个 row 输出一个分割掩码。
三分支结构:
Mask 分支:为每个 row 输出一个分割掩码。
Box 分支 & Score 分支:与 SiamRPN 中的一样,生成k个锚框,预测每个位置上的对象概率与回归kkk个锚框的x,y,h,w。
方法
Siamese 网络
与SiamFC不同的是,为了让每个 Row 编码更丰富的信息,将原始的简单互相关操作 ⋆\star⋆ 替换为深度互相关 ⋆d\star_d⋆d 即每个 channel 单独计算互相关,最后拼接在一起,得到一个与template特征和search特征相同深度的响应图。
第二部分
由于三分支结构中的MaskBranch与二 ...
最优化 - 单纯形法
优化多维无约束问题的一种数值方法,主要思想是,从一个初始基本可行解开始,迭代改进可行解,直到达到最优。
基本概念
对于线性规划的标准形式:
minf=cxs.t.Ax=bx≥0\begin{aligned}
\min &&f &= cx \\
\text{s.t.}&& Ax&=b \\
&& x &\geq 0
\end{aligned}
mins.t.fAxx=cx=b≥0
通过变换行,使其前 mmm 行线性无关,对矩阵AAA的分割,得到基矩阵 BBB 与非基矩阵 NNN:
Am×n=(P1,P2,...,Pm,Pm+1,...,Pn)=(B,N)\underset{m \times n}{A} = (P_1,P_2,...,P_m,P_{m+1},...,P_n) = (B,N)
m×nA=(P1,P2,...,Pm,Pm+1,...,Pn)=(B,N)
同样对CCC、xxx进行划分得到(CB,CN)(C_B,C_N)(CB,CN) (xB,xN)(x_B,x_N)(xB,x ...

DETR
概述
基于Transformer的端到端目标检测网络
由于Transformer强大的上下文理解能力,无需人工设计锚框与NMS,能够检测出先前方法nms会误判的两个目标重叠的情形。对于大型物体与Faster RCNN相比具有优势,但是小物体检测不如Faster RCNN
一次预测所有对象
DETR 由四个部分组成:
用于提取紧凑特征表示的CNN backbone
Transformer 编码器,以加上位置编码的打散的CNN输出特征作为输入。
Transformer 解码器,以编码器的输出与一个Object Query(可学习的位置编码)作为输入。
进行最终检测的简单FFN。
方法
CNN Backbone
使用传统CNN(丢弃了分类层的ResNet)将 H0×W0×3H_0 \times W_0 \times 3H0×W0×3 的输入图像映射到 H032×W032×2048\frac{H_0}{32} \times \frac{W_0}{32} \times 204832H0×32W0×2048 的特征图。
Transformer Encoder
使用 1×11 ...
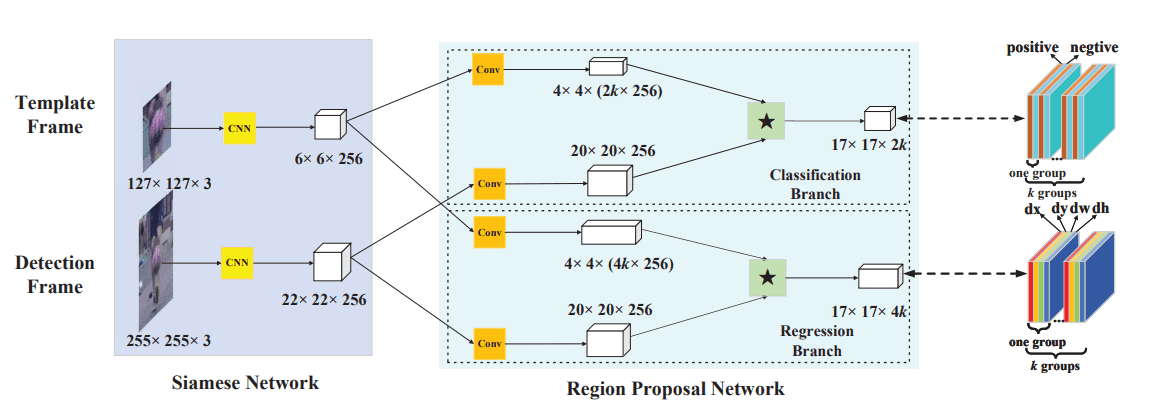
SiamRPN
概述
将目标检测中的RPN网络应用在目标追踪。
两部分:
用于特征提取的Siamese网络(使用预训练的AlexNet)。
预测边缘框和置信度的 RPN 网络。
方法
Siamese 网络
共享参数的 AlexNet:
第一帧给定的 127×127127 \times 127127×127 模板图像,输入Siamese网络,得到 256×6×6256 \times 6 \times 6256×6×6 的特征图,文中记为 φ(z)\varphi(z)φ(z)。
当前帧 255×255255 \times 255255×255 的Search Image,输入Siamese网络,得到 256×22×22256 \times 22 \times 22256×22×22 的特征图,φ(x)\varphi(x)φ(x)。
RPN 网络
kkk 为每个位置上生成的锚框数量。
分类分支
将Siamese的输出 φ(z)\varphi(z)φ(z) 和 φ(x)\varphi(x)φ(x) 分别通过 3×33 \times 33×3 卷积层(两个卷积参数不共享)映射到 4×4×(2k ...
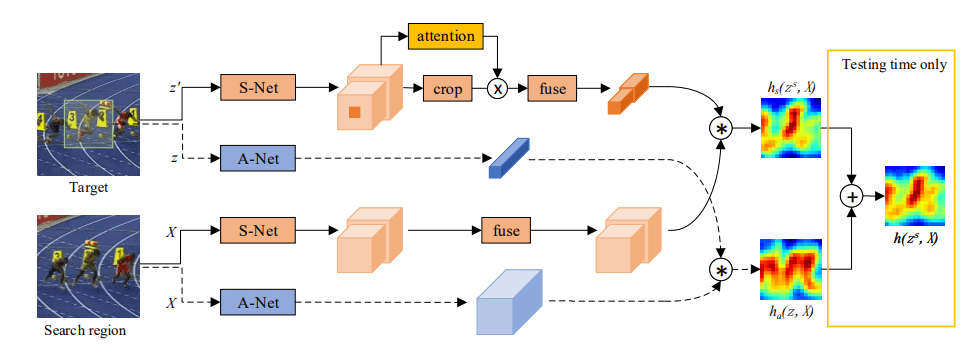
SA-Siam
简介
本文基于SiamFC,主要提升SiamFC的泛化能力
SA-Siam 拥有两个分支
外观(Appearance)分支:与SiamFC一致。
语义(Semantic)分支:输出特征是high-level,健壮的,不易受外观影响,使模型能够剔除无关的背景,可以补充外观特征。
用于语义分支的通道注意力机制:对在特定目标中发挥更重要作用的通道给予更高的权重。
方法
Semantic Branch
对于搜索
输入图像 XXX 经过一个CNN(AlexNet)fs(⋅)f_s(\cdot)fs(⋅),将最后两层的特征拼接以获得不同层次的信息。然后使用 1×11 \times 11×1 卷积网络 g(⋅)g(\cdot)g(⋅) 在相同层中融合特征。
g(fs(X))g(f_s(X))
g(fs(X))
对于目标
不直接使用目标模板zzz,而使用以目标模板 zzz 为中心,与搜索输入XXX一样大的图像 zsz^szs 作为CNN的输入(以获得更多上下文信息)得到 fs(zs)ff_s(z^s)ffs(zs)f。同时以 fs(z)f_s(z)fs(z) 来表示fs(zs)f ...