EnsembleLearning
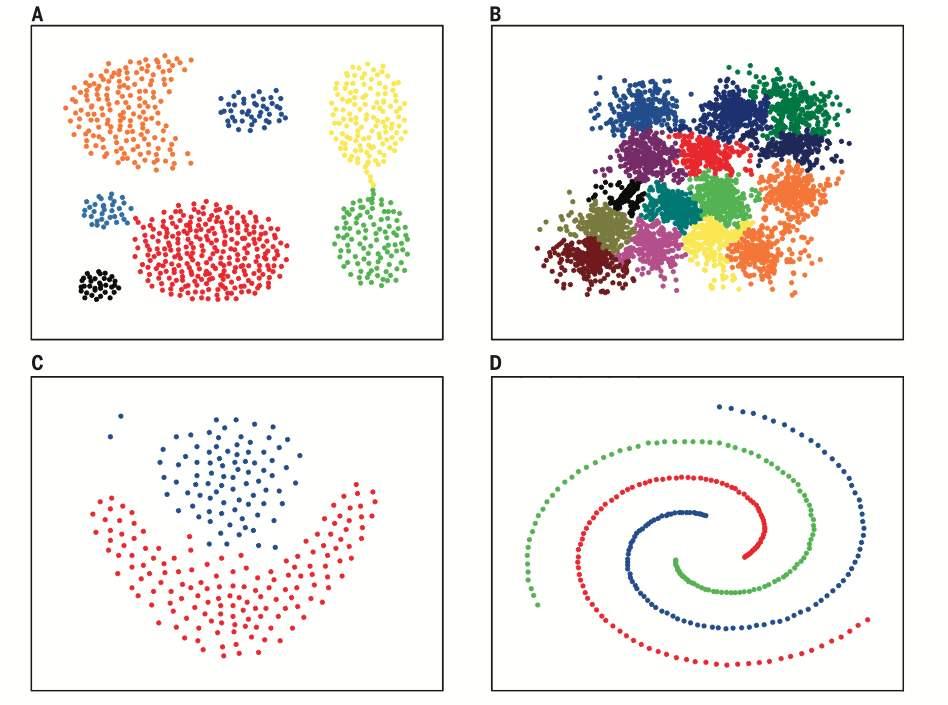
多个学习器被训练来解决同一个问题。往往比单个学习器好很多。
一般结构为:先产生一组“个体学习器”,再用某种策略将它们结合起来。集成学习大致可分为三大类:
- Bagging(Bootstrap Aggregating):有放回的抽样原始数据集,分别训练多个学习器,将多个模型的输出加权平均作为最终结果。e.g. 随机森林
- Boosting:通过在训练新模型实例时更注重先前模型错误分类的实例来增量构建集成模型。e.g. AdaBoost GBDT
- Stacking:训练一个模型用于组合其他各个模型。
Bagging
随机森林
给定
- 数据集
- 树数量 ,树数量越多,泛化能力越强,但是过大训练速度慢提升也很小。
- 每棵树所能使用的最大特征数
算法过程:
- 循环训练个决策树,
- 从数据集 随机选取个特征得到的子集 (显然数据集中可能会有重复的样本)
- 使用训练一个决策树
- 对于分类任务选择票数最多的(众数),对于回归任务取平均数
我们希望每个弱分类器相关性小,以从不同角度进行判断,增加泛化能力。
Boosting
Ada Boost
首先训练一个弱学习器,对于已经能够很好分类的样本,减少这些样本的注意力,后续的弱学习器专注那些分类错的样本,这样训练出一组学习器,组合在一起,就能对所有类型的样本都有不错的效果。
为了使对不同样本有不同的注意力,我们需要每个样本对应有一个权值,被初始化为同一个值,,通过将分类器的损失函数乘以样本所对应的权值,来达到这样的效果。
训练完一个弱学习器后,根据其分类误差计算出一个系数,用于更新权值分布与组合学习器,更新权值:$$w_{n}:=\frac{w_{n}}{Z_{n}}\exp(-\alpha_{m} y_{n}\hat{y}_{n})$$其中, ,用于规范化。
依次训练完一组学习器后,将他们线性组合在一起:
,最终分类结果G(x)=\sign(f(x))
Gradient Boosting Decision Tree(GBDT)
提升树:每一棵树都是在上一棵树的残差基础上建立的,即真实值是,此时一个弱学习器预测为,残差为,下一个弱学习器拟合这个残差。
to be continue…
All articles in this blog are licensed under CC BY-NC-SA 4.0 unless stating additionally.
Related Articles